

作者:Morty Lai
近年來,大型語言模型(英語:Large Language Model,LLM)的技術突飛猛進,使得各種以「AI」為主軸的服務應運而生,開啟人工智慧新篇章,也反應出大型語言模型的可靠性,為產業和民眾帶來前所未有的創造力和智慧。除了使用OpenAI的ChatGPT、Google的Gemini和Microsoft 的Copilot等第三方服務外,現在也可以在私有環境中運行 Mamba、Meta的LLaMA 和 微軟的Phi-3 等語言模型。相較於這些公開的第三方服務,使用自己運行的大型語言模型,不僅不必將資訊透過網路傳輸到公開的服務端,大大降低數據外流的風險,還能根據特定需求進行微調,進而強化模型在專業領域的生成品質。
現今的大型語言模型生成高品質內容,其中重要的成功因素之一就是採用「自回歸(auto-regressive)」的生成方式。自回歸生成方式就像是文字接龍,模型會根據使用者的提示內容,先通過嵌入(embedding)、編碼(encoding)、解碼(decoding)等多層次處理,計算出生成候選字詞的機率分佈。在獲得機率分佈後,模型會選擇要生成的「下一個」字詞,並將選擇出的字詞重新帶入上述的運作流程。不斷地經由上述的反覆操作,直到整個文本完成。因為每一步生成的內容,都會考慮先前生成的內容,這也讓生成內容的連貫性和準確性獲得了提昇。雖然自回歸生成方法能夠生成高品質的內容,但同時也是生成速度的瓶頸之一。因為,模型每次都選擇生成一個字詞,而每次的生成都要考慮先前的生成內容。
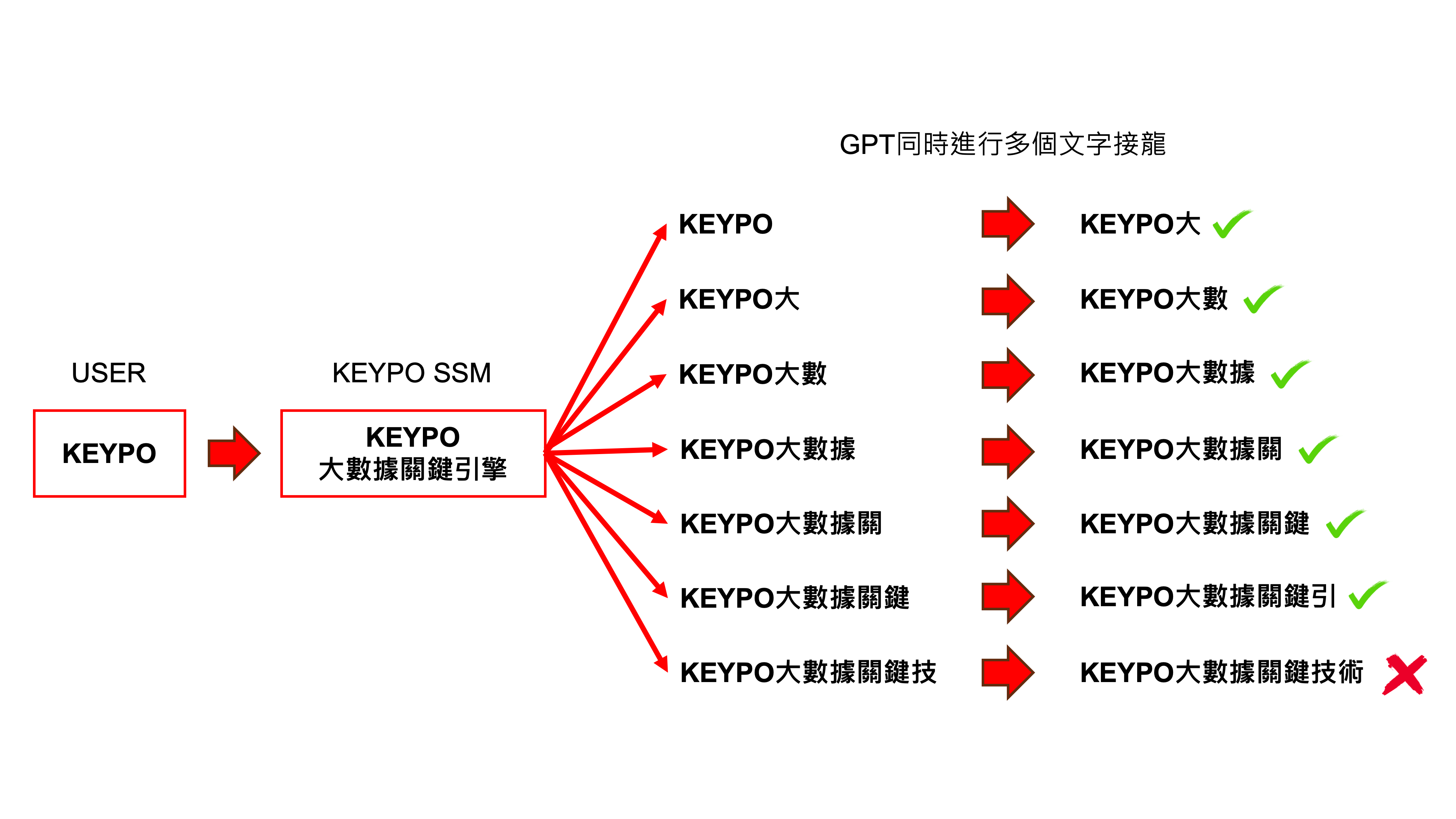
為求在不失生成品質情況下,提升大型語言模型的生成速度,投機解碼(Speculative Decoding)的相關機制也蘊育而生,並能廣泛運用在許多大型語言模型上,而非單一的特定模型。投機解碼的一個核心概念,就是運用快速的小型投機模型(small speculative model, SSM) 預先生成內容,然後讓大型語言模型以平行處理的方式,對於小型投機模型的生成內容進行文字接龍。最終,從所有生成的內容中選擇最合適的部分作為結果。舉例來說,若使用者輸入「KEYPO」,而小型投機模型很快的產生出「大數據關鍵技能」,則可以將「KEYPO大」、「KEYPO大數」、「KEYPO大數據」、「KEYPO大數據關」、「KEYPO大數據關鍵」、「KEYPO大數據關鍵技」、「KEYPO大數據關鍵技能」,都交由大型語言模型預測下一個字。若大型語言模型分別生成「大」、「數」、「據」、「關」、「鍵」、「技」、「能」、「。」,則可以發現大型語言模型預測「KEYPO大數據關鍵」的下一個字是「引」,與小型投機模型生成的「技」不同,但「大數據關鍵」是小型投機模型和大型語言模型皆相同的部份,因此可以使用「大數據關鍵引」作為最終結果的一部分,並再次進行上述的步驟。如此一來,若能妥善運用小型投機模型的生成內容,大型語言模型便有機會在生成單一字詞的時間內產生一段相同品質的內容,進而大幅提高生成速度。
《KEYPO Suite》中的《KEYPO大數據關鍵引擎》全新升級,不僅是提供以大型語言模型為基礎的輿情分析服務,更是輔以多種先進的AI人工智慧技術,打造「GPT智能報告」功能,並將生成時間從一分多鐘加速到僅需數十秒。這正是大數據股份有限公司強大的技術團隊,結合大型語言模型的軟體工程技術和演算技巧運用的成果。使用者將能體驗到最新大型語言模型所帶來的分析洞察結果,未來也將持續運用更多的最新技術,提供企業輕鬆追蹤、分析輿情,即時聆聽民眾真實的網路聲量,並深入洞察消費者關鍵情報,搶佔市場致勝先機。
想了解更多《KEYPO Suite》強大服務?請立即與我們聯絡以取得更多資訊。